Paper: RF-GPT: A Spectrogram-Driven Visual Pathway for Radio-Frequency Language Models
Authors: Hang Zou, Yu Tian, Bohao Wang, Lina Bariah, Samson Lasaulce, Chongwen Huang, Merouane Debbah
TL;DR — We built RF-GPT, a radio-frequency language model that converts RF signals into spectrograms and feeds them through a vision-language model, enabling natural-language reasoning about wireless signals. Key results:
- 99.6% wireless technology recognition across 6 technologies (5G NR, LTE, WLAN, UMTS, DVB-S2, Bluetooth)
- General-purpose VLMs score near-random on all RF tasks — confirming they have zero RF prior
- Fully synthetic training pipeline — no real-world RF data collection needed
- Competitive with CNN/ViT baselines trained for 30 epochs — RF-GPT needs only 3
Imagine
Close your eyes for a moment and picture this: an AI system that can listen to the electromagnetic spectrum around you. Not hear sounds — but perceive the invisible ocean of radio waves that saturates every room, every street, every city on the planet.
You point a software-defined radio at a busy urban band, and this AI instantly tells you: “I see three 5G NR base stations — two in FR1 using 30 kHz subcarrier spacing, one in FR2. There’s a Wi-Fi 6E access point serving 12 users across three resource units. Two Bluetooth Low Energy devices are hopping across the ISM band. And there’s a DVB-S2 satellite downlink at the edge of the band, QPSK modulated with pilot insertion enabled.”
It doesn’t just classify — it understands. It can tell you which signals overlap in time and frequency, estimate how many users each base station is serving, identify the modulation and coding scheme of each transmission, and flag anomalies that deviate from standard behavior. Ask it a follow-up question — “Is there any interference between the Wi-Fi and the Bluetooth?” — and it answers in plain language, grounding its reasoning in the actual spectral evidence.
Now scale this up. Deploy thousands of these RF-aware AI agents across a network. They monitor spectrum usage in real time, negotiate access autonomously, detect unauthorized transmissions, verify standard compliance, and coordinate across bands — all through natural language interfaces that human operators and higher-level AI agents can query, inspect, and override. This is the vision of AI-native 6G: networks where intelligence permeates the physical layer, not just the management plane.
This is not science fiction. The architectures, the training methods, and the compute exist today. But there is one massive obstacle: every large AI model in existence is completely blind to radio-frequency signals. GPT-4, Claude, Gemini, Llama — none of them have ever seen an RF waveform. They have zero prior knowledge of what a 5G signal looks like, how modulations differ, or what interference means in the time-frequency plane. Ask the most powerful vision-language model on the planet to analyze a spectrogram, and it will confidently hallucinate something that has nothing to do with what’s actually there.
So how do we give machines their first glimpse of the invisible spectrum? We start by teaching a language model to read spectrograms.
The Gap: Why LLMs Can’t See Radio Waves
The AI world has modalities covered — or so it seems. Large language models process text. Vision-language models handle images and text. Audio models like Whisper transcribe speech. But there is an entire modality that no foundation model has been systematically trained on: radio-frequency signals.
RF signals are fundamentally different from anything these models have seen. They live in complex baseband — a signal $s(t) = I(t) + jQ(t)$ with in-phase and quadrature components, sampled at rates from megahertz to gigahertz. This is not audio (which is real-valued and low-bandwidth). It is not a natural photograph. It is an entirely different physical modality with its own structure: time-frequency patterns shaped by modulation schemes, protocol standards, multi-user scheduling, and propagation physics.
To quantify this gap, we directly tested state-of-the-art VLMs — Qwen2.5-VL (3B and 7B) and GPT-5 — on RF spectrogram tasks. We gave them carefully designed prompts explicitly stating that the input is an RF spectrogram, described the axes, and asked for structured answers. The results were unambiguous: near-random accuracy across every benchmark. These models either collapsed onto a single label or produced uniform guesses, regardless of what the spectrogram actually contained.
The takeaway is clear: a bigger model will not solve this. The problem is not capacity — it is the absence of RF data in pretraining. The solution requires the right representation, the right data, and the right training strategy.
This modality gap is exactly what motivated RF-GPT. In our earlier work on TelecomGPT, we showed that domain-adapted LLMs can dramatically outperform general-purpose models on text-based telecom tasks. But TelecomGPT operates on text — standards documents, QA, code. It cannot process the physical layer. RF-GPT closes this gap by bringing RF signals directly into the language model.
RF-GPT: A Radio-Frequency Language Model
We propose the concept of a radio-frequency language model (RFLM): a foundation model that takes an RF signal as input and generates natural-language analysis as output. RF-GPT is our instantiation of this concept.
The core insight is simple but powerful: RF signals can be represented as spectrograms — two-dimensional time-frequency images computed via the Short-Time Fourier Transform (STFT):
$$S[k,t] = \sum_{n} x[n] \, w[n - tH] \, e^{-j2\pi kn/F}$$where $x[n]$ is the complex IQ sequence, $w[\cdot]$ is a window function, $F$ is the FFT size, and $H$ is the hop size. The magnitude spectrogram $|S[k,t]|$ is converted to dB scale and mapped to an image — and suddenly, an RF signal becomes something a vision encoder can process.
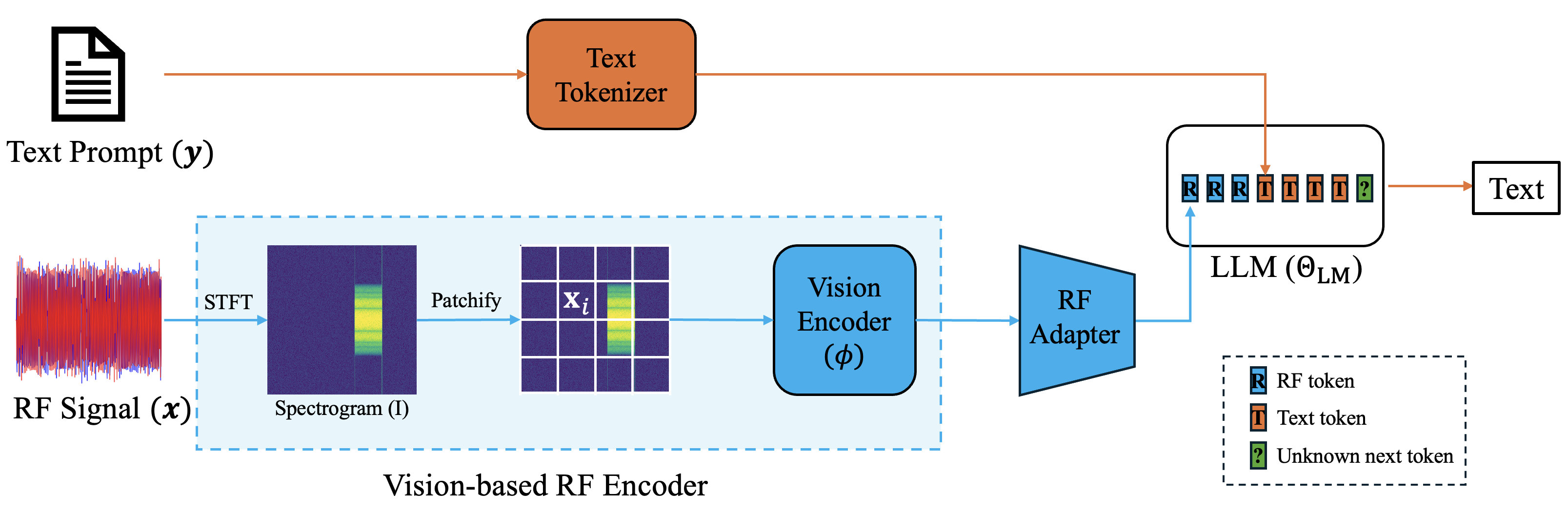
This is the architecture (see the cover figure above):
- IQ to spectrogram: complex waveform $\rightarrow$ STFT $\rightarrow$ magnitude in dB $\rightarrow$ $512 \times 512$ image
- Vision encoder: a pretrained ViT partitions the spectrogram into $14 \times 14$ patches, producing 1,369 RF tokens
- RF adapter: a lightweight linear projection maps RF tokens into the LLM embedding space
- LLM backbone: a decoder-only Transformer (Qwen2.5-VL) generates text conditioned on the RF token prefix
The language model receives the RF tokens exactly as it would receive image tokens in a standard VLM — no architectural changes required. The entire vision-language model ecosystem is reused; what changes is what the vision encoder sees. We fine-tune Qwen2.5-VL at both 3B and 7B scales on 12000 RF scenes and 0.625M RF instructions — the entire RF grounding takes a few hours of training.
Why vision and not audio? This is a natural question. Audio language models (like Whisper or Qwen2-Audio) also process waveforms. But they use 1D tokenizers optimized for speech — temporal structure matters, but spectral structure is secondary. For RF signals, the 2D time-frequency structure is everything: modulation patterns, resource block allocations, multi-user scheduling, and inter-signal overlap are all encoded in the spectrogram plane. A vision encoder preserves this structure; an audio tokenizer would destroy it.
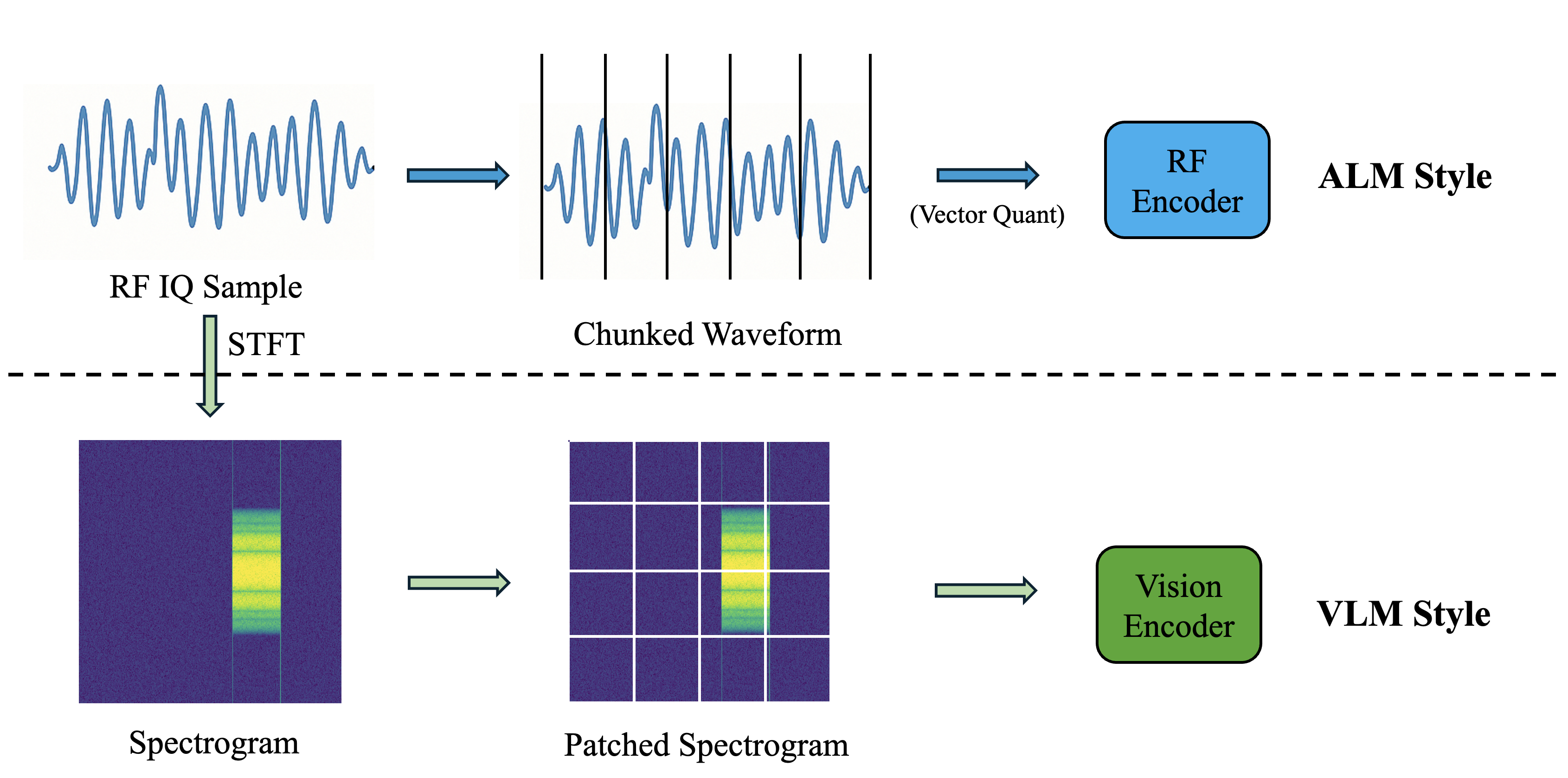 Comparison of audio-style (top) and vision-style (bottom) RF tokenization. The vision pathway preserves the 2D time-frequency structure that carries the information relevant to RF understanding.
Comparison of audio-style (top) and vision-style (bottom) RF tokenization. The vision pathway preserves the 2D time-frequency structure that carries the information relevant to RF understanding.
Training Without a Single Real Signal
Building an RFLM faces a chicken-and-egg problem: you need labeled RF-text pairs to train, but creating them requires either expensive hardware campaigns with expert annotators, or an existing RFLM to generate captions — which doesn’t exist yet. Real over-the-air data collection is not only expensive but raises reproducibility concerns, suffers from class imbalance (common signals dominate while rare edge cases are hard to capture), and provides ground truth that is often incomplete (the true transmitter configuration is hidden inside proprietary equipment).
We cut this knot with a fully synthetic pipeline built on three stages:
1. Standards-Compliant Waveform Generation
We use MATLAB’s wireless toolbox family to generate standards-compliant RF waveforms for six major wireless technologies: 5G NR, LTE, UMTS, WLAN (Wi-Fi 6/7), DVB-S2, and Bluetooth. For each technology, we randomly sample valid configurations (bandwidth, numerology, modulation scheme, number of users, resource allocations, etc.) and run the standards-compliant waveform generator. Invalid configurations are rejected by the toolbox itself, ensuring every sample obeys the relevant 3GPP/ETSI/IEEE specification.
 Spectrograms of six wireless standards generated by our pipeline. Each technology has distinct visual signatures — from the structured resource grid of 5G NR (top left) to the frequency-hopping bursts of Bluetooth (bottom right).
Spectrograms of six wireless standards generated by our pipeline. Each technology has distinct visual signatures — from the structured resource grid of 5G NR (top left) to the frequency-hopping bursts of Bluetooth (bottom right).
2. Deterministic Captioning
Every generated waveform comes with complete metadata — the exact configuration used by the simulator. We convert this metadata into structured, hierarchical captions organized in five information levels:
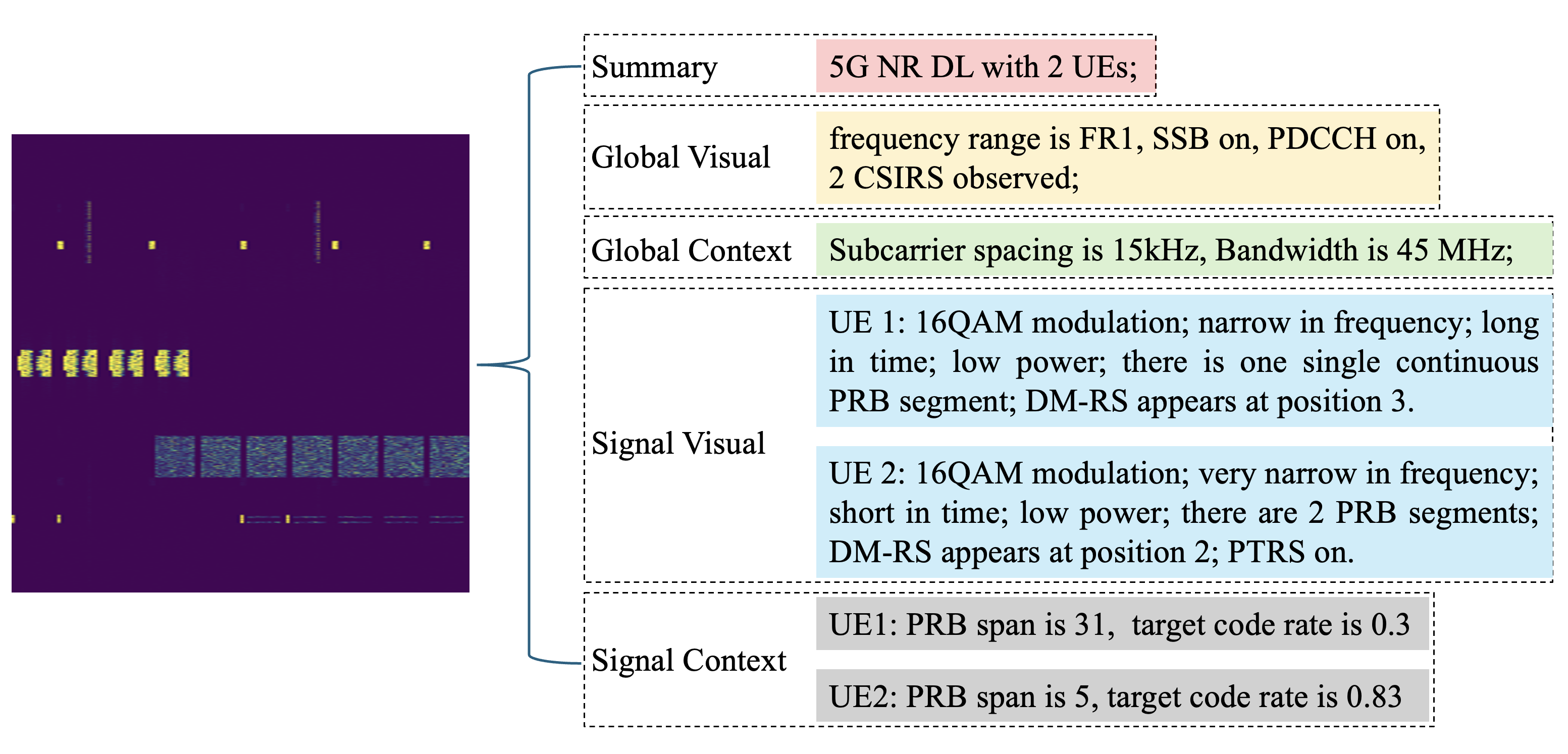 Our five-level caption hierarchy: from high-level summary down to per-signal context. Each level exposes progressively more detail about the RF scene.
Our five-level caption hierarchy: from high-level summary down to per-signal context. Each level exposes progressively more detail about the RF scene.
- Summary: high-level scene description (“a 5G NR downlink with 2 UEs”)
- Global visual: patterns visible in the spectrogram (SSB blocks, CSI-RS bursts, overall occupancy)
- Global context: scene-level parameters from metadata (bandwidth, subcarrier spacing)
- Signal visual: per-signal visual attributes (time/frequency extent, relative power)
- Signal context: per-signal technical details (DM-RS settings, PRB allocations)
Because captions are derived deterministically from simulator parameters, they are exact — no human annotation errors, no hallucination risk, full reproducibility.
3. LLM-Based Instruction Synthesis
Dense captions are technically correct but unsuitable for instruction tuning: they are monolithic, always in the same format, and don’t match how a human would actually query an RF scene. We solve this by feeding captions to a text-only LLM, which generates diverse instruction-answer pairs across multiple task templates: signal counting, modulation recognition, technology identification, overlap analysis, information extraction, and open-ended explanation.
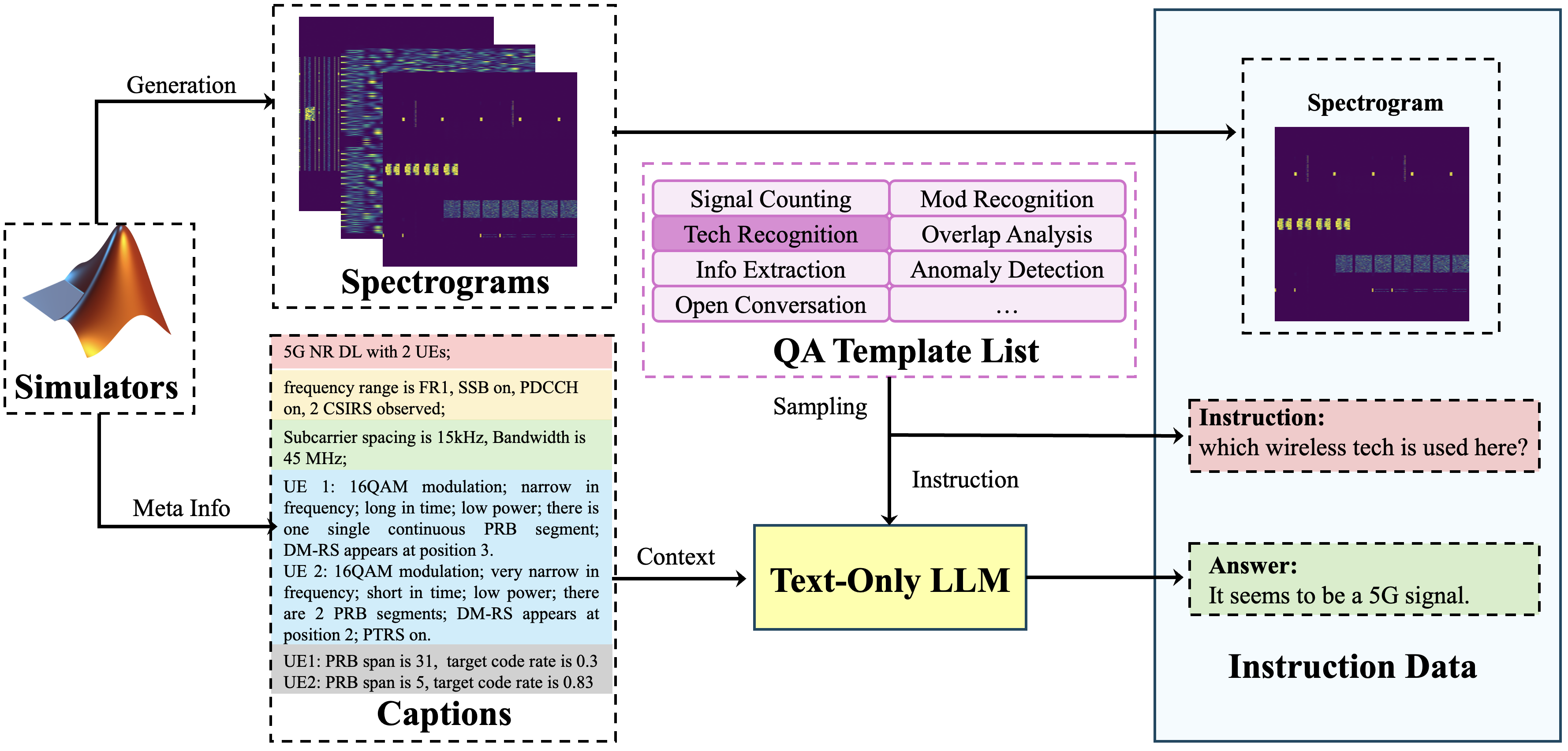 The instruction synthesis pipeline: simulators generate spectrograms with metadata, a deterministic captioner produces structured descriptions, and a text-only LLM converts these into diverse instruction-answer pairs.
The instruction synthesis pipeline: simulators generate spectrograms with metadata, a deterministic captioner produces structured descriptions, and a text-only LLM converts these into diverse instruction-answer pairs.
The result is a large, diverse RF instruction corpus where every answer is grounded in exact simulator metadata, but the questions vary naturally in phrasing, difficulty, and task type. We also leverage TorchSig to add wideband modulation diversity beyond the six wireless technologies.
Five Benchmarks, One Clear Story
General-Purpose VLMs Have Zero RF Prior
Before diving into numbers, consider this qualitative example. We show the same 5G NR downlink spectrogram to both Qwen2.5-VL-7B (a general-purpose VLM) and RF-GPT-7B (our fine-tuned model):
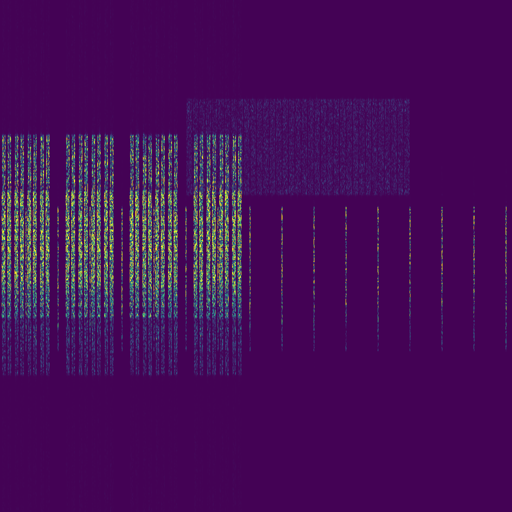
Qwen2.5-VL-7B: “This spectrogram displays a variety of radio-frequency signals. In the central region, there are several prominent vertical lines, suggesting strong narrowband transmissions that could be from amateur radio stations, radar systems, or other point-to-point communication devices…”
— A confident hallucination with zero useful information.
RF-GPT-7B: “The spectrogram shows a single-UE 5G NR downlink capture in the FR2 band. An SSB is present, following the Case D transmission pattern, and the PDCCH is also active. No CSI-RS traces are visible. The data payload occupies one continuous block of PRBs…”
— A grounded, accurate, and detailed analysis.
This is not a cherry-picked example. Across all five benchmarks, general-purpose VLMs score near-random while RF-GPT demonstrates strong RF understanding:
| Benchmark | Task | RF-GPT-7B | Baseline VLMs |
|---|---|---|---|
| WBMC | Modulation classif. (E / M / H) | 82 / 74 / 48% | ~2% |
| WBOD | Overlap detection (E / M / H) | 92 / 88 / 72% | ~15% |
| WTR | Technology recognition | 99.6% | ~5% |
| WNUC | WLAN user counting | ~70% | ~23% |
| NRIE | 5G NR info extraction | ~76% | ~20% |
E / M / H = Easy / Medium / Hard difficulty levels.
These benchmarks span from simple classification (WTR) to structured information extraction (NRIE), demonstrating that RF-GPT is a generalist, not a one-trick classifier. Even the smaller RF-GPT-3B achieves 99.4% on WTR and 80.0% on WBMC-Easy, showing that RF grounding works across model scales.
Modulation Classification
Wireless Blind Modulation Classification (WBMC) tests three difficulty levels. Easy asks for the modulation family (e.g., QAM vs. PSK); Medium provides a candidate list; Hard requires identifying the exact modulation from all 57 classes. RF-GPT-7B scores 82 / 74 / 48% on Easy / Medium / Hard, while the best VLM barely reaches ~2%. Beyond modulation labels, RF-GPT also correctly counts the number of signals in a spectrogram ~98% of the time — something general-purpose VLMs almost never achieve.
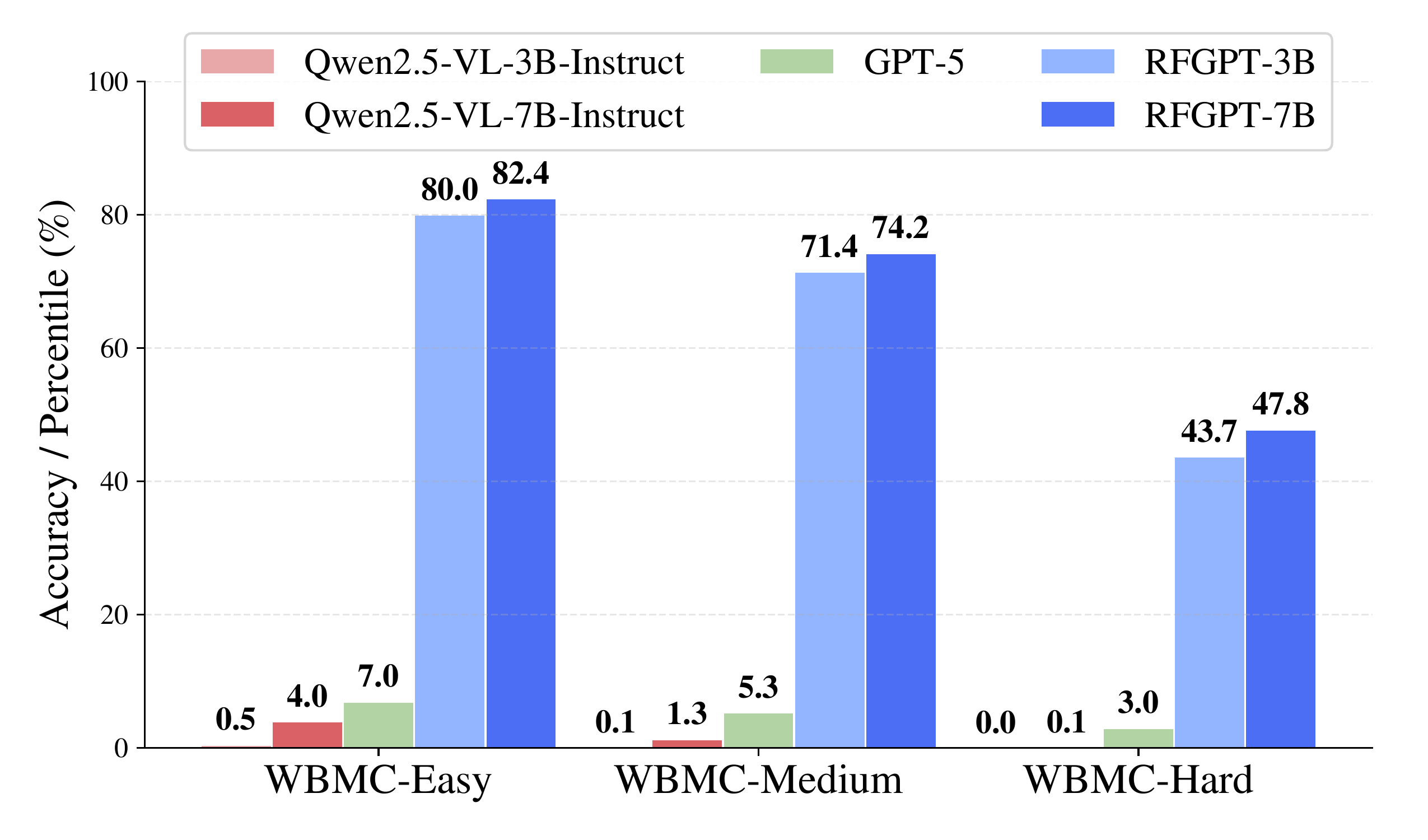 Modulation classification accuracy across three difficulty levels. RF-GPT handles increasingly fine-grained recognition; VLMs produce near-random outputs.
Modulation classification accuracy across three difficulty levels. RF-GPT handles increasingly fine-grained recognition; VLMs produce near-random outputs.
Overlap Detection
Wireless Blind Overlap Detection (WBOD) asks whether signals overlap in time and frequency, also at three difficulty levels. Easy requires a global yes/no answer; Medium asks about pairwise overlap between specific signals; Hard demands quantified overlap strength. RF-GPT-7B achieves 92 / 88 / 72% across these levels. This task requires spatial reasoning about time-frequency structure — understanding where signals sit and whether their energy intersects — a capability that general-purpose VLMs completely lack.
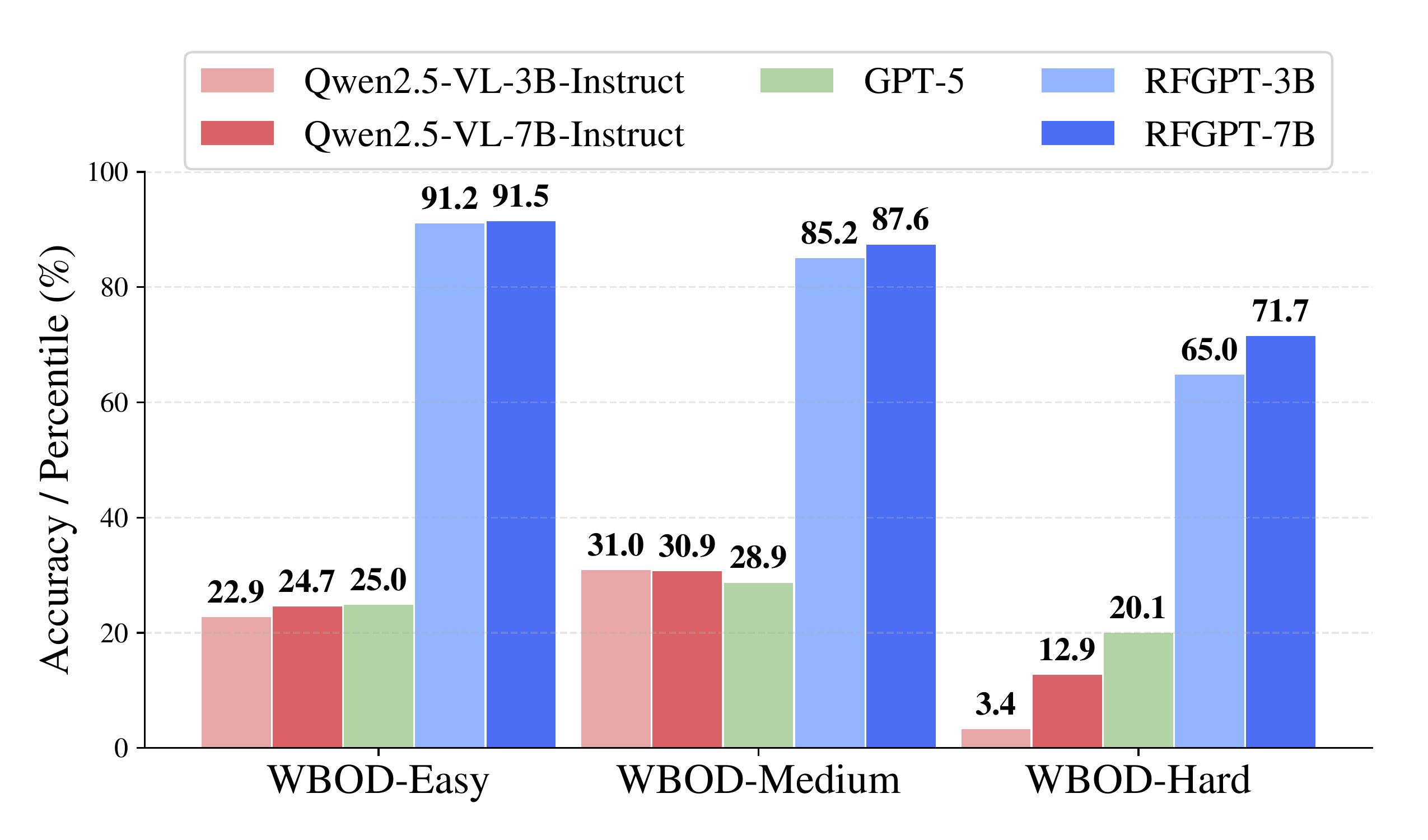 Overlap detection accuracy across three difficulty levels. RF-GPT reasons about spatial relationships in the time-frequency plane; VLMs cannot.
Overlap detection accuracy across three difficulty levels. RF-GPT reasons about spatial relationships in the time-frequency plane; VLMs cannot.
Technology Recognition: Near-Perfect
The flagship result is Wireless Technology Recognition (WTR): given a spectrogram, identify the wireless technology and link direction. RF-GPT-7B achieves 99.64% joint accuracy across all six technologies. The per-technology breakdown shows RF-GPT at near-100% across all six technologies, while general-purpose VLMs collapse onto one or two dominant labels:
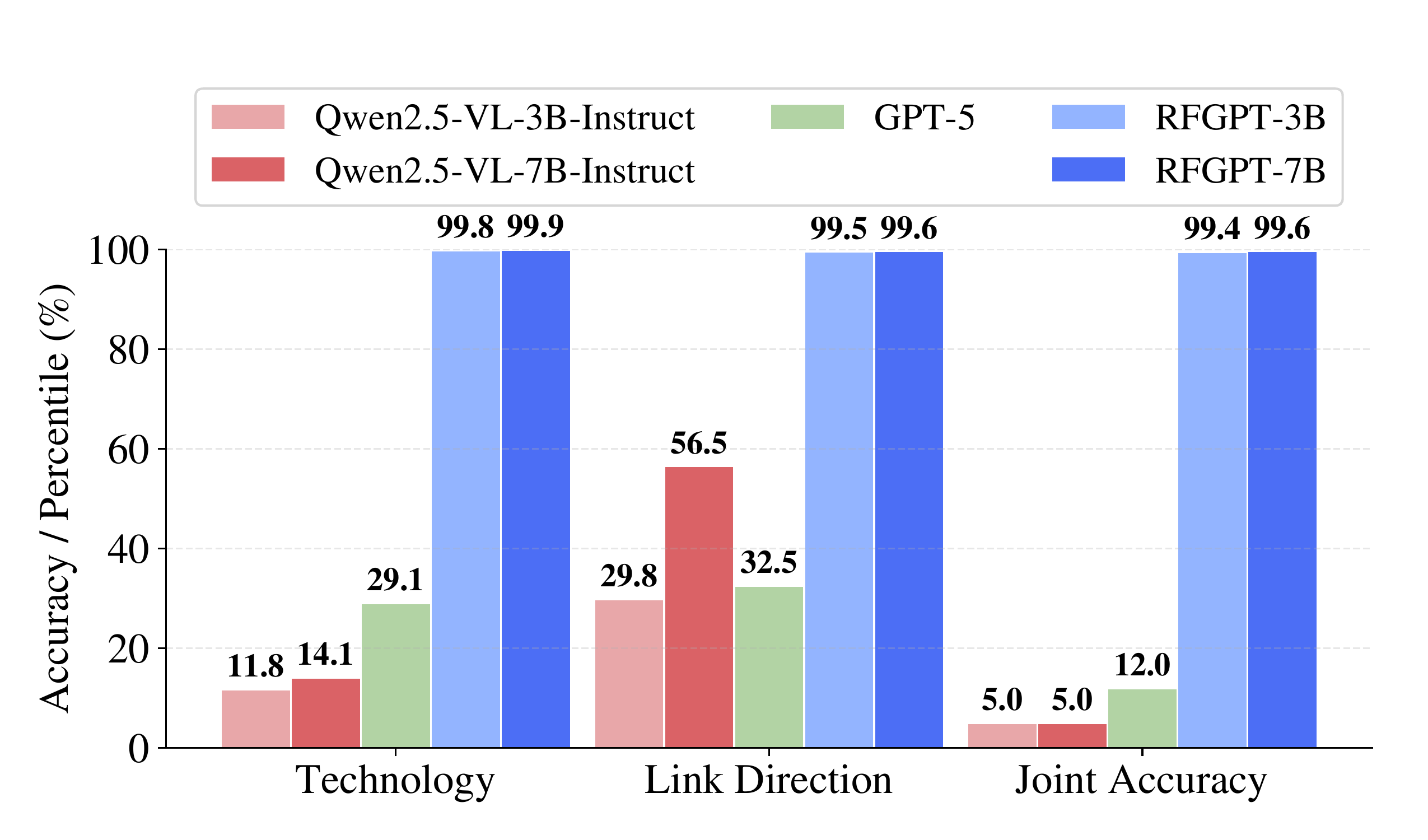 Per-technology accuracy for wireless technology recognition. RF-GPT achieves near-perfect accuracy on every technology; VLMs fail catastrophically.
Per-technology accuracy for wireless technology recognition. RF-GPT achieves near-perfect accuracy on every technology; VLMs fail catastrophically.
The confusion matrix tells the same story — it is almost perfectly diagonal:
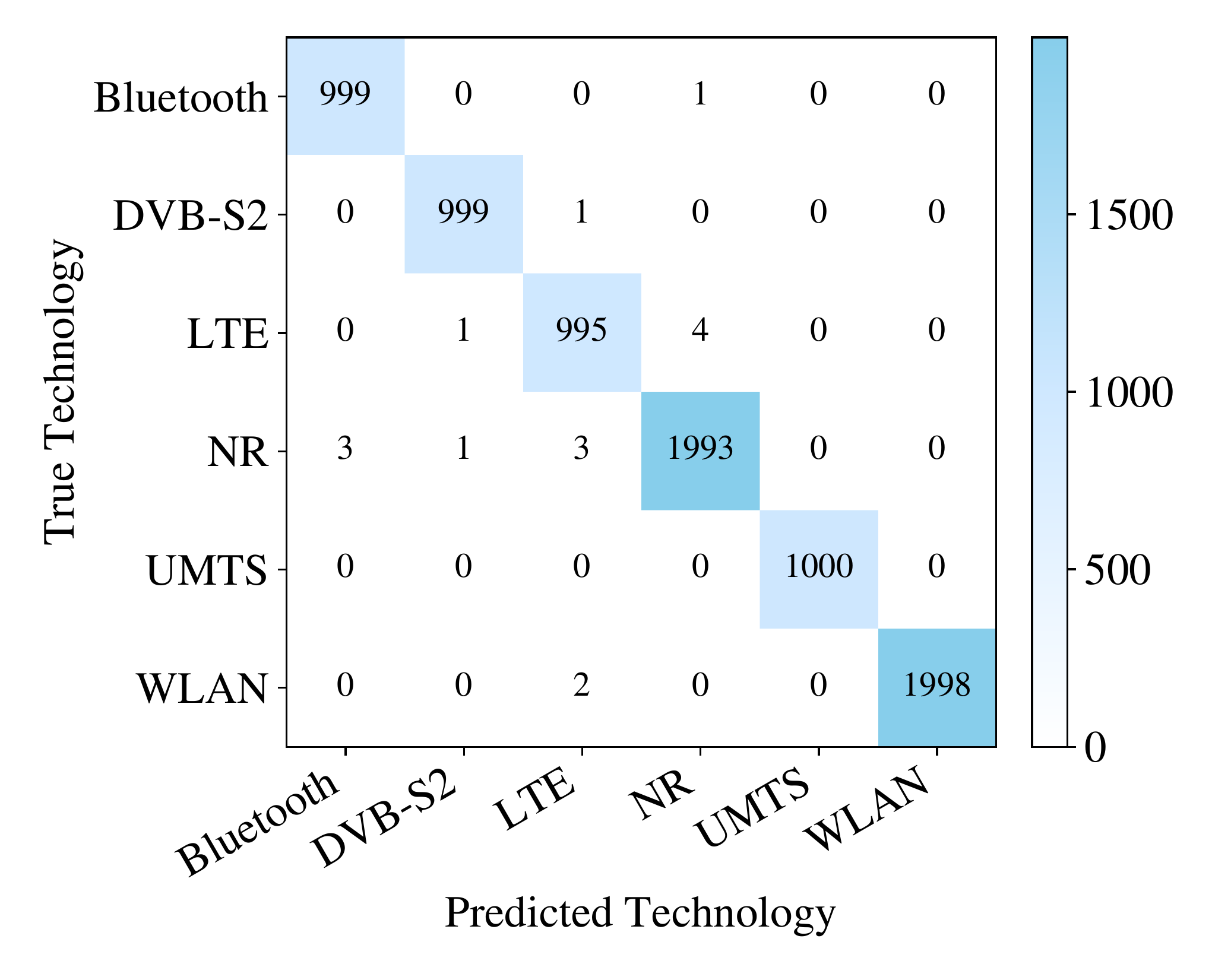 Confusion matrix for wireless technology recognition. RF-GPT correctly classifies Bluetooth, DVB-S2, LTE, 5G NR, UMTS, and WLAN with near-zero cross-technology confusion.
Confusion matrix for wireless technology recognition. RF-GPT correctly classifies Bluetooth, DVB-S2, LTE, 5G NR, UMTS, and WLAN with near-zero cross-technology confusion.
User Counting
Wireless Number of User Counting (WNUC) asks the model to count the number of users in 802.11ax and 802.11be spectrograms. RF-GPT-7B averages ~70% across both standards. 11be is consistently easier because each user occupies a distinct resource unit, making users visually separable. 11ax uses MU-MIMO with shared resource units, so users overlap spatially and counting requires understanding allocation patterns rather than simply counting visual blobs.
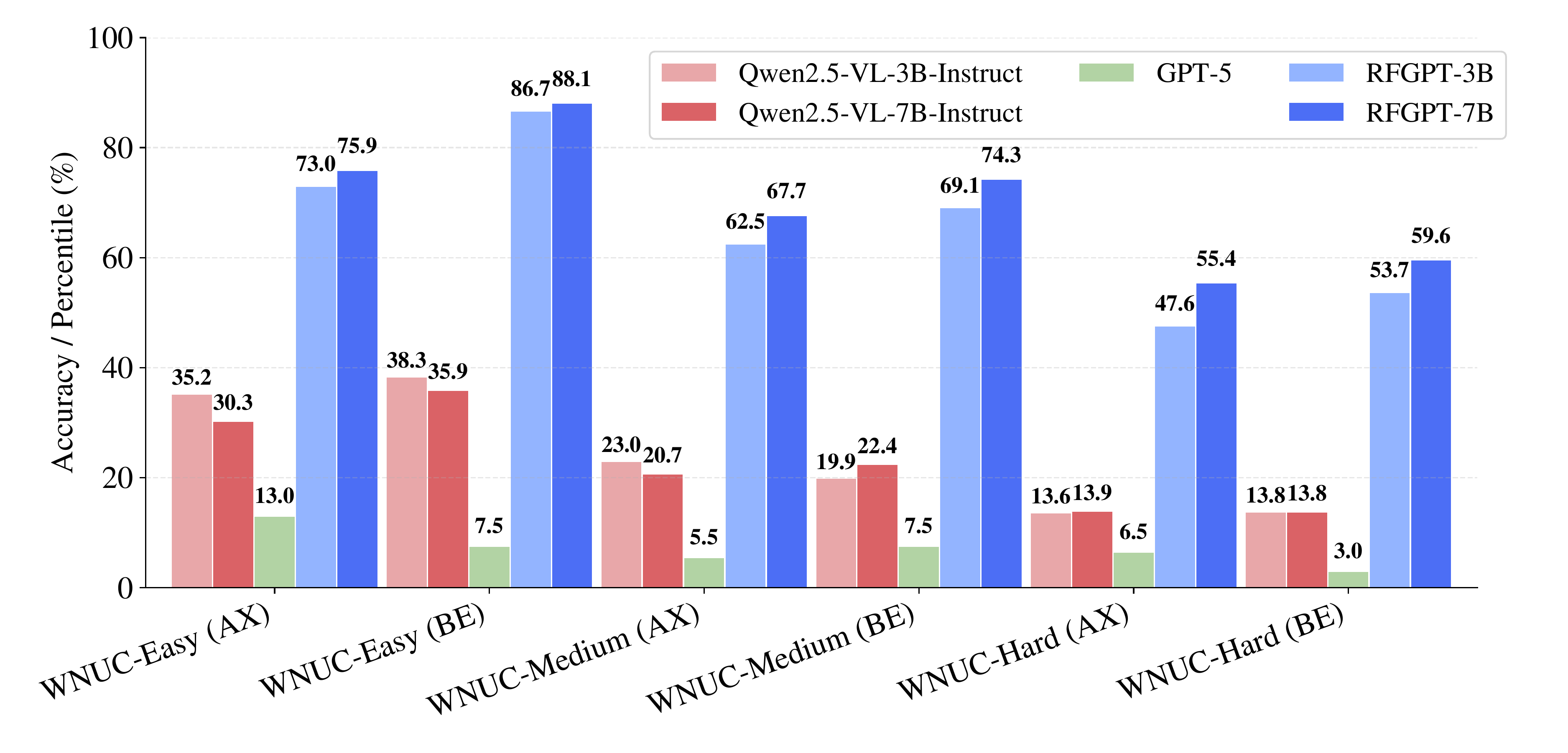 User counting accuracy for 802.11ax and 802.11be. Distinct resource-unit allocation in 11be makes counting easier; shared RUs in 11ax MU-MIMO make it harder.
User counting accuracy for 802.11ax and 802.11be. Distinct resource-unit allocation in 11be makes counting easier; shared RUs in 11ax MU-MIMO make it harder.
5G NR Information Extraction
5G NR Information Extraction (NRIE) is the most structured benchmark: given a 5G NR downlink spectrogram, extract the subcarrier spacing, SSB pattern, and counts of UE-specific, CSI-RS, and SRS allocations. RF-GPT achieves near-perfect accuracy on SCS and SSB pattern identification, with moderate performance on the counting tasks. A single model handles all attributes through natural language — no task-specific output heads required.
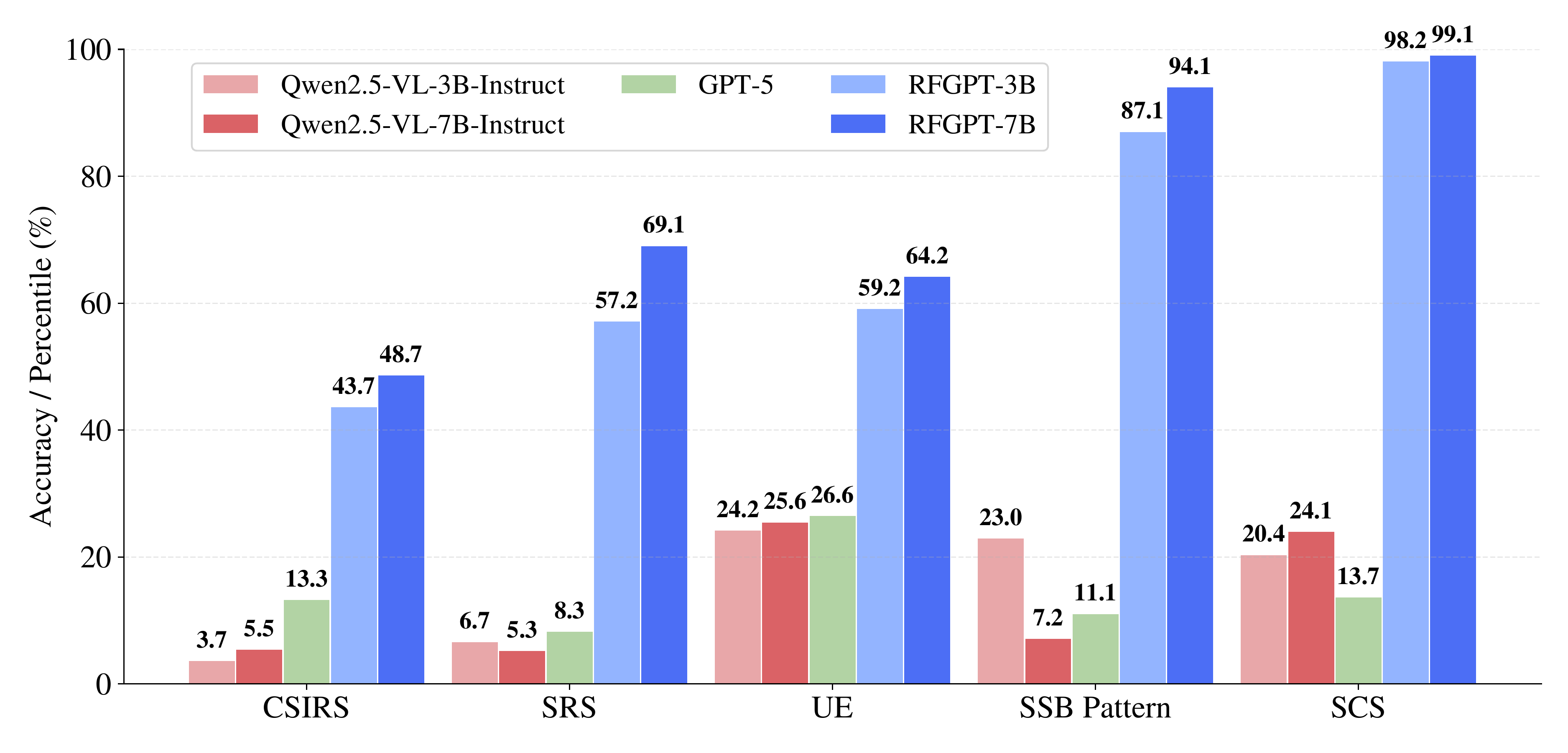 5G NR information extraction accuracy by attribute. Structural parameters (SCS, SSB) are near-perfect; counting tasks are harder but still far beyond VLM baselines.
5G NR information extraction accuracy by attribute. Structural parameters (SCS, SSB) are near-perfect; counting tasks are harder but still far beyond VLM baselines.
Robustness and Efficiency
Two additional findings deserve mention:
Robustness to RF impairments. We swept four impairment types (IQ imbalance, PA nonlinearity, carrier frequency offset, and multipath fading) from clean to severe levels — well beyond what the model saw during training. RF-GPT maintains high accuracy under CFO, PA distortion, and fading. Only IQ imbalance causes meaningful degradation (~6 percentage points), because it introduces mirror-frequency artifacts that directly confuse visual structure. Crucially, the model was trained only with mild impairments (λ ≤ 0.3); its robustness to severe levels is emergent, not explicitly taught.
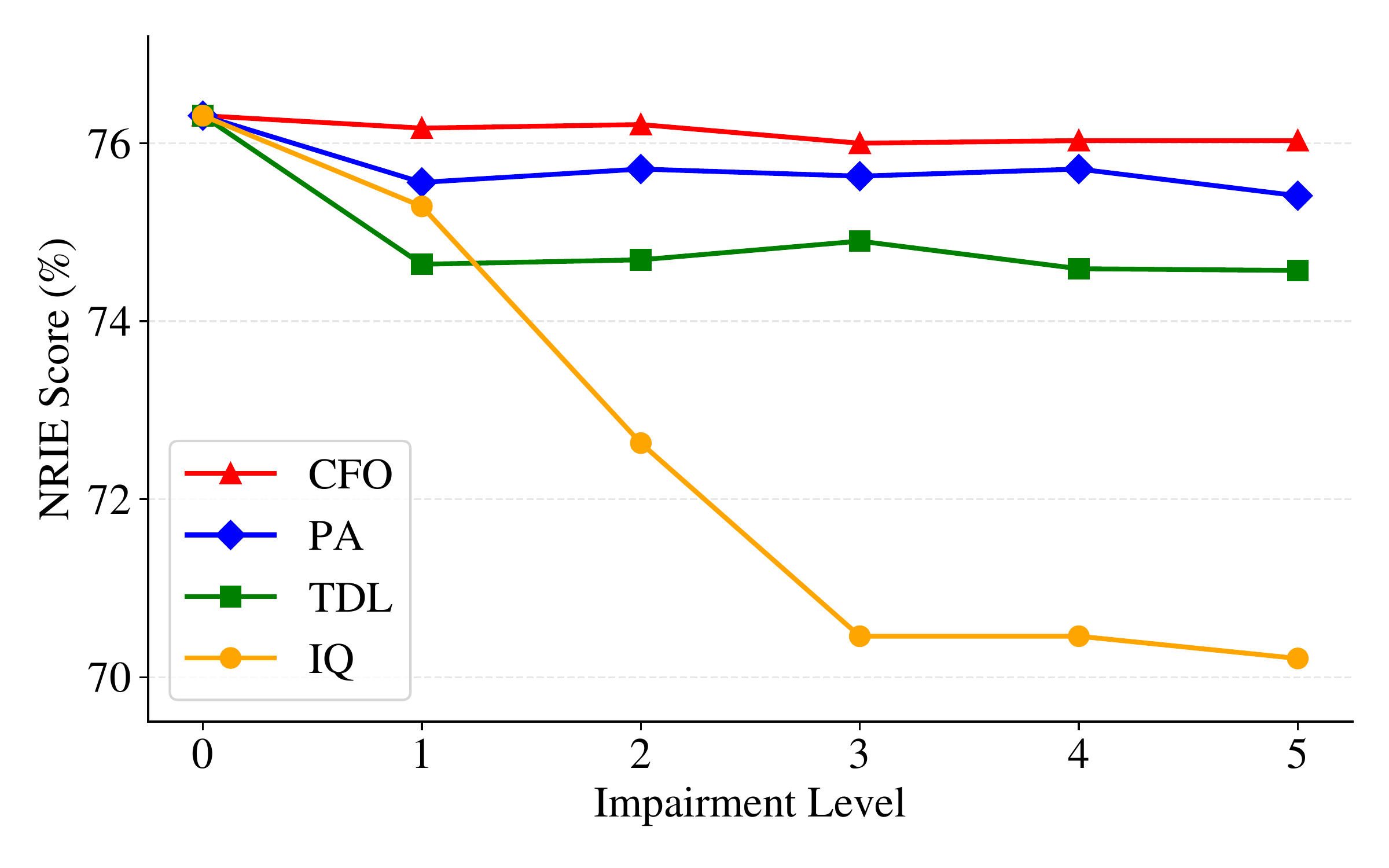 Accuracy under increasing RF impairment severity. CFO, PA distortion, and fading cause mild degradation; IQ imbalance has the largest impact due to mirror-frequency artifacts.
Accuracy under increasing RF impairment severity. CFO, PA distortion, and fading cause mild degradation; IQ imbalance has the largest impact due to mirror-frequency artifacts.
Data efficiency. RF-GPT-7B matches or exceeds the strongest CNN/ViT-H baselines on the NRIE benchmark — but with 3 fine-tuning epochs instead of 30 from-scratch training epochs. The pretrained vision encoder provides powerful feature representations that transfer effectively to RF spectrograms, making fine-tuning fast and efficient. No task-specific heads are needed — a single architecture with a single training objective handles all five benchmarks.
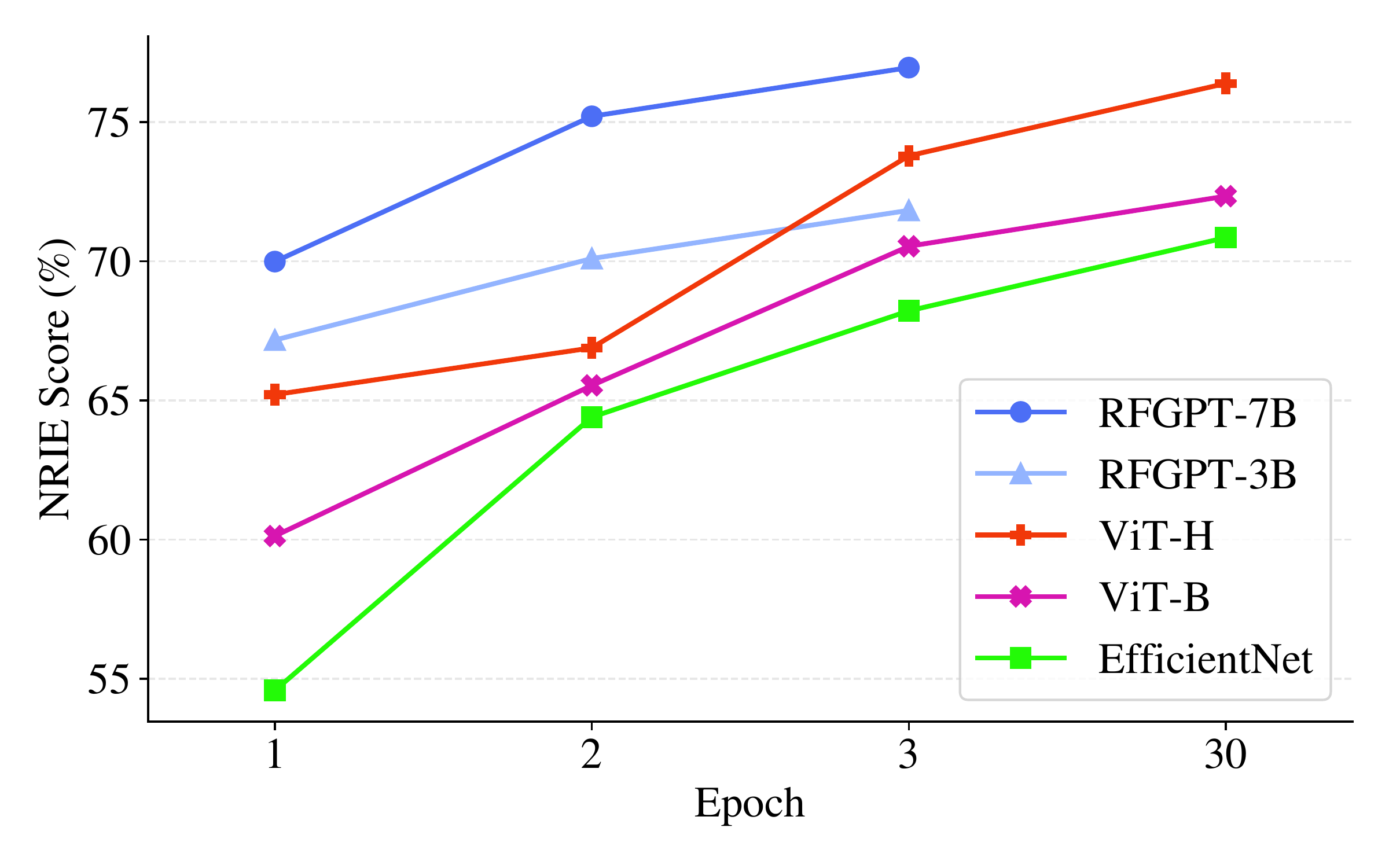 Training efficiency comparison. RF-GPT-7B at 3 epochs (77%) surpasses ViT-H at 30 epochs (76.4%), demonstrating the power of pretrained vision-language representations for RF tasks.
Training efficiency comparison. RF-GPT-7B at 3 epochs (77%) surpasses ViT-H at 30 epochs (76.4%), demonstrating the power of pretrained vision-language representations for RF tasks.
Key Takeaways
Spectrograms are the Rosetta Stone for RF+AI. By converting IQ waveforms to time-frequency images, we can leverage the entire vision-language model ecosystem — pretrained encoders, attention mechanisms, and instruction-tuning recipes — without designing custom RF architectures.
VLMs have zero RF knowledge out of the box. This is not a fine-tuning convenience — it is a necessity. Without domain-specific training, the most capable VLMs produce confident but meaningless analysis of RF spectrograms.
Synthetic data can be better than real data. When ground truth comes directly from simulator parameters, labels are exact. No annotation errors, no ambiguity, full reproducibility. The synthetic-first approach also enables systematic diversity: we control the distribution over technologies, configurations, and edge cases.
One model, five benchmarks. Unlike CNN/ViT baselines that require separate architectures and output heads for each task, RF-GPT handles modulation classification, overlap detection, technology recognition, user counting, and information extraction through a single instruction-following interface.
Three epochs are enough. Vision encoders pretrained on large-scale image data provide strong feature representations that transfer to spectrograms. RF grounding is fast and compute-efficient.
What’s Next
RF-GPT is a first step — a proof of concept built entirely on synthetic, standards-compliant signals. Reaching the vision from the opening of this post requires several leaps:
- Real over-the-air signals — bridging the sim-to-real gap with noise, propagation effects, hardware imperfections, and unknown emitters
- Open-set recognition — identifying signals the model has never seen during training, not just classifying from a known set
- Temporal reasoning — tracking signals over time, detecting transient events, and understanding protocol state machines across multiple frames
- Agentic capabilities — an RF-GPT that controls a software-defined radio, adjusts tuning and bandwidth, and actively explores the spectrum based on what it finds
We also plan to integrate RF-GPT into spectrum monitoring prototypes and AI-native network management systems, moving from synthetic proof-of-concept toward practical RF intelligence.
We gave a language model its first glimpse of the electromagnetic spectrum. The view is already remarkable. Imagine what it will see next.
This post summarizes our work on RF-GPT. If you’re working on RF/AI integration, spectrum monitoring, or multimodal models for signal processing, feel free to connect with me on LinkedIn.