Paper: TelecomGPT: A Framework to Build Telecom-Specific Large Language Models
Authors: Hang Zou, Qiyang Zhao, Yu Tian, Lina Bariah, Faouzi Bader, Thierry Lestable, Merouane Debbah
TL;DR — We built a three-stage pipeline (continual pre-training → instruction tuning → alignment) to adapt open-source LLMs for telecom. Key results:
- 75.3% on 3GPP document classification — nearly 2x GPT-4o’s 38.9%
- Outperforms GPT-4 on telecom math equation reconstruction (49.45 vs 49.38 MathBERT score)
- 4x improvement on telecom code infilling over base Llama3-8B-Instruct
- All built on 7-8B parameter models — a fraction of GPT-4’s size and cost
Motivation
Large Language Models like GPT-4 and Llama-3 are impressive generalists, but they struggle with the telecom domain. Ask GPT-4 to classify a 3GPP technical specification into the correct working group, and it gets it right less than 40% of the time. Ask it to infill a missing equation in a wireless communications paper, and it barely outperforms a coin flip.
Why? Telecom is a deeply specialized field with its own vocabulary, mathematical conventions, protocol structures, and standards ecosystem. The 3GPP corpus alone spans tens of thousands of pages of dense, interconnected specifications. General-purpose LLMs simply haven’t seen enough of this material — and even when they have, they haven’t been trained to reason about it effectively.
TelecomGPT addresses this gap head-on. Rather than building a telecom LLM from scratch (prohibitively expensive), we developed a systematic pipeline to adapt existing open-source LLMs — Llama-2-7B, Mistral-7B, and Llama-3-8B — into telecom specialists. Along the way, we also built the evaluation infrastructure that the field was missing.
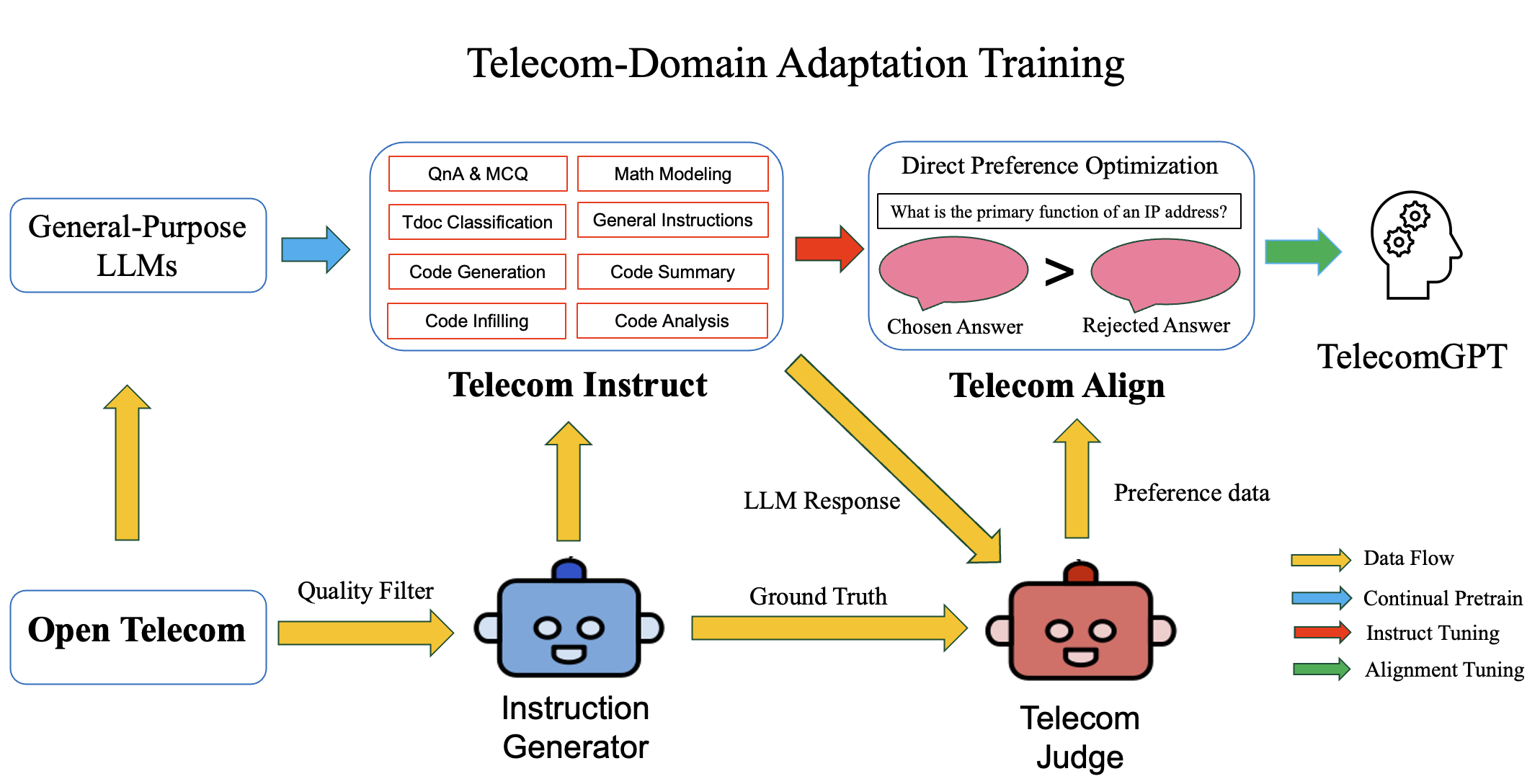
The Three-Stage Pipeline
Our adaptation pipeline consists of three sequential stages, each building on the previous one (see the cover figure above).
Stage 1: Continual Pre-training
The first challenge is data. We built OpenTelecom, a curated pre-training corpus of 1.68 billion tokens drawn from diverse telecom sources:
| Source | Tokens (M) | Share |
|---|---|---|
| ArXiv papers | 893 | 53.2% |
| Code (GitHub) | 260.1 | 15.5% |
| Patents (C4) | 253.2 | 15.1% |
| 3GPP Standards | 193 | 11.5% |
| StackExchange | 51.9 | 3.1% |
| Wikipedia | 18.9 | 1.1% |
| IEEE Standards | 7.5 | 0.5% |
| Books | 1.9 | 0.1% |
To ensure relevance, we applied a sophisticated filtering pipeline using over 700 domain-specific keywords spanning wireless communications, signal processing, networking protocols, and standards terminology. The dataset was deduplicated and quality-filtered to avoid contaminating the model with irrelevant content.
Continual pre-training uses standard causal language modeling — the model learns to predict the next token, but now on telecom-specific text. This stage injects domain vocabulary and factual knowledge into the model’s parameters.
Stage 2: Instruction Tuning (SFT)
Raw knowledge isn’t enough — the model needs to know how to use it. We created TelecomInstruct, a diverse instruction dataset covering:
- Multiple-choice QA — answering questions about telecom standards and research
- Open-ended QA — free-form answers to telecom questions
- Document classification — identifying which 3GPP working group a text belongs to
- Math equation generation — filling in missing equations from wireless communications papers
- Code tasks — summarization, analysis, infilling, and generation of telecom-related code
We used QLoRA (Quantized Low-Rank Adaptation) for parameter-efficient fine-tuning with rank $r = 512$ and scaling factor $\alpha = 256$, training for 3 epochs. This keeps the computational cost manageable — about 1.5 hours on 8 GPUs.
Stage 3: Alignment Tuning (DPO)
The final stage uses Direct Preference Optimization (DPO) to align the model’s outputs with human preferences. We created TelecomAlign, a preference dataset where each example contains a prompt, a preferred (chosen) response, and a rejected response.
In plain terms, DPO teaches the model to increase the probability of good responses and decrease the probability of bad ones — without needing a separate reward model. It optimizes the policy directly using the objective:
$$\mathcal{L}_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) = -\mathbb{E}\left[\log \sigma\left(\beta \log \frac{\pi_\theta(y_w | x)}{\pi_{\text{ref}}(y_w | x)} - \beta \log \frac{\pi_\theta(y_l | x)}{\pi_{\text{ref}}(y_l | x)}\right)\right]$$where $\pi_\theta$ is the policy being trained, $\pi_{\text{ref}}$ is the reference (SFT) model, $y_w$ and $y_l$ are the preferred and rejected responses, and $\beta = 0.1$ controls the deviation from the reference policy.
Five Novel Evaluation Benchmarks
A recurring problem in telecom AI research is the lack of standardized evaluation. We introduced five benchmark categories specifically designed for the telecom domain.
Model name key: In the tables below, suffixes indicate training stages applied — TP = continual pre-training, TI = instruction tuning, TA = alignment tuning (DPO). For example, Llama3-8B-TI-TA means Llama3-8B after both instruction tuning and alignment.
1. Telecom MCQ (Multiple-Choice Questions)
500 questions across five categories: Lexicon, Research Overview, Research Publications, Standards Overview, and Standards Specifications. Notice how our instruction-tuned models close the gap to GPT-4, especially on Lexicon where Llama3-8B-TI scores a perfect 96%:
| Model | Lexicon | Research | Standards Spec. | Overall |
|---|---|---|---|---|
| GPT-4o | 92.0 | 79.5 | 62.8 | 78.0 |
| GPT-4 | 92.0 | 78.0 | 60.0 | 75.0 |
| Llama3-8B-Instruct | 80.0 | 69.8 | 50.0 | 64.8 |
| Llama3-8B-TI | 96.0 | 74.9 | 56.4 | 71.2 |
| Mistral-7B-Instruct | 84.0 | 65.0 | 51.0 | 62.0 |
| Mistral-7B-TI | 84.0 | 70.7 | 51.1 | 65.2 |
Our instruction-tuned Llama3 model achieves 71.2% overall — closing a significant portion of the gap to GPT-4 (75%) despite being 25x smaller.
2. 3GPP Document Classification
Classifying technical specification text into 16 working groups across three TSG categories (RAN, SA, CT). This is where TelecomGPT truly shines — look at the CT column, where general-purpose models completely fail:
| Model | RAN | SA | CT | Overall |
|---|---|---|---|---|
| GPT-4o | 44.1 | 47.6 | 17.3 | 38.9 |
| GPT-3.5 | 42.9 | 48.6 | 16.3 | 38.5 |
| Llama3-8B-Instruct | 39.1 | 38.7 | 16.2 | 33.4 |
| TelecomGPT-8B | 82.8 | 68.8 | 73.6 | 75.3 |
TelecomGPT nearly doubles GPT-4o’s accuracy on this task. General-purpose models simply lack the fine-grained understanding of 3GPP’s organizational structure that our domain-specific training provides.
3. Telecom Math Modeling
Perhaps our most novel benchmark: given a research paper with an equation removed, can the model reconstruct it? We evaluate ~600 equations from 170 papers using MathBERT embeddings for semantic similarity scoring. Pay attention to the $\geq$90% column — the share of near-perfect reconstructions:
| Model | Avg. Score | $\geq$90% | $\geq$50% |
|---|---|---|---|
| GPT-4 | 49.38 | 3.77% | 50.35% |
| Llama3-8B-Instruct | 40.78 | 2.51% | 34.45% |
| Llama3-8B-TI-TA | 49.45 | 9.52% | 50.73% |
| Mistral-7B-Instruct | 35.54 | 1.53% | 29.43% |
| Mistral-7B-TI-TA | 48.11 | 7.22% | 49.26% |
After both instruction tuning and alignment, our Llama3-based TelecomGPT slightly outperforms GPT-4 on average score (49.45 vs 49.38) and produces substantially more near-perfect reconstructions (9.52% vs 3.77% at $\geq$90% threshold).
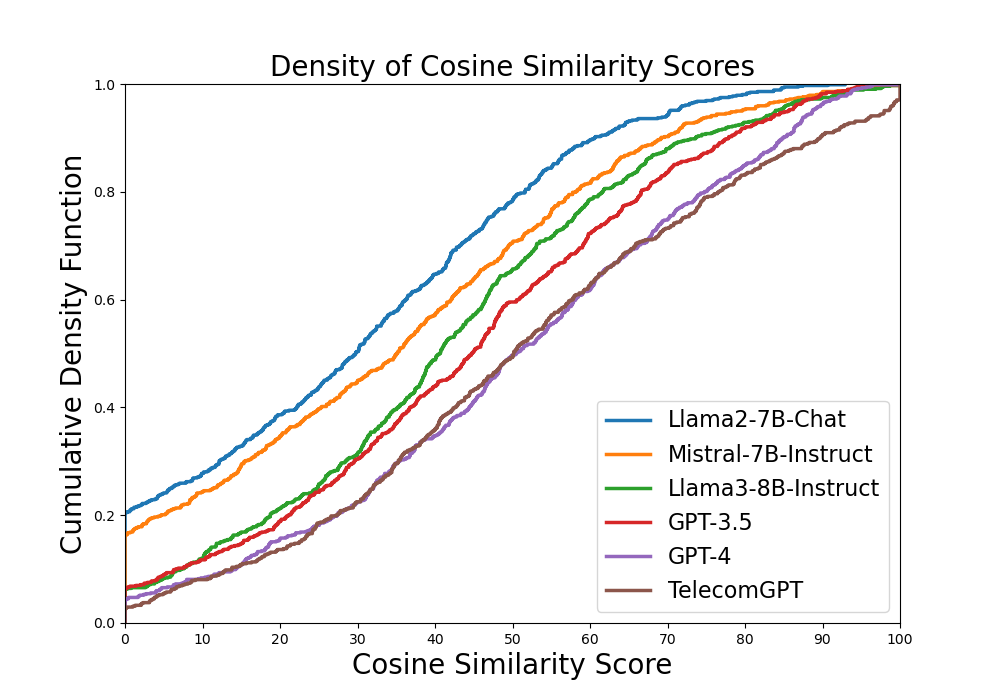 Figure 2: Cumulative density function of MathBERT cosine similarity scores. TelecomGPT’s curve (brown) closely tracks or exceeds GPT-4 (purple) across the full score range, while significantly outperforming all other open-source base models.
Figure 2: Cumulative density function of MathBERT cosine similarity scores. TelecomGPT’s curve (brown) closely tracks or exceeds GPT-4 (purple) across the full score range, while significantly outperforming all other open-source base models.
4. Telecom Code Tasks
Four subtasks: code summarization, code analysis, code infilling, and code generation — all using telecom-specific code (MATLAB signal processing, Python simulations, etc.). The Infilling column tells the clearest story:
| Model | Summary (R1) | Analysis (R1) | Infilling (R1) | Generation (R1) |
|---|---|---|---|---|
| Llama3-8B-Instruct | 0.320 | 0.334 | 0.113 | 0.191 |
| Llama3-8B-TI-TA | 0.517 | 0.405 | 0.434 | 0.271 |
| Mistral-7B-Instruct | 0.364 | 0.398 | 0.106 | 0.194 |
| Mistral-7B-TI-TA | 0.575 | 0.547 | 0.439 | 0.260 |
The improvements on code infilling are striking: from 0.113 to 0.434 ROUGE-1 for Llama3, almost a 4x improvement. This demonstrates that the model has learned the patterns and conventions of telecom-specific code.
5. Instruction Following
We evaluate on both general telecom instructions and protocol-specific instructions (e.g., “Explain the RRC connection setup procedure”). The Open QA column reveals the starkest gap between base and adapted models:
| Model | Open QA (R1) | General Instr. (R1) | Protocol Instr. (R1) |
|---|---|---|---|
| Llama3-8B-Instruct | 0.055 | 0.188 | 0.204 |
| Llama3-8B-TI-TA | 0.417 | 0.414 | 0.353 |
The open-ended QA improvement — from 0.055 to 0.417 — is particularly noteworthy. The base instruct model essentially could not answer open-ended telecom questions; TelecomGPT can.
What Each Training Stage Contributes
A natural question: is every stage necessary? Our ablation analysis shows each stage serves a distinct purpose:
| Stage | What it adds | Evidence |
|---|---|---|
| Continual Pre-training (TP) | Domain vocabulary and factual knowledge | ~4% MCQ accuracy boost for Llama2 |
| Instruction Tuning (TI) | Task-following ability across telecom tasks | Dramatic improvements across all benchmarks |
| Alignment (TA) | Response quality and conciseness | Consistent gains on math modeling and open QA |
The biggest jump comes from instruction tuning — but alignment provides meaningful refinements, particularly for generation-heavy tasks like math modeling and open-ended QA.
Key Takeaways
Domain adaptation works. A 7-8B parameter model, properly adapted, can match or exceed GPT-4 on specialized telecom tasks — at a fraction of the inference cost.
Data curation matters more than data volume. Our 1.68B token pre-training corpus is tiny by modern standards, but careful filtering with domain keywords ensures high relevance.
Evaluation infrastructure is as important as the model. Before TelecomGPT, there was no standardized way to measure how well an LLM understands telecom. Our five benchmarks cover the breadth of skills that a telecom AI assistant needs.
The 3GPP classification result is a wake-up call. GPT-4o at 38.9% vs TelecomGPT at 75.3% — this isn’t a marginal improvement. It demonstrates that domain-specific training unlocks capabilities that scale alone cannot provide.
Open-source models can be competitive. By building on Llama and Mistral, our entire pipeline is reproducible and extensible by the research community.
What’s Next?
TelecomGPT is a framework, not a final product. Future directions include:
- Scaling up — applying the pipeline to larger base models (70B+)
- Multimodal telecom AI — incorporating network diagrams, signal visualizations, and protocol flow charts
- RAG integration — combining TelecomGPT with retrieval over live 3GPP specifications
- Agent capabilities — enabling TelecomGPT to interact with network simulators and configuration tools
If you’re interested in the details, check out the full paper on arXiv.
This post summarizes our work on TelecomGPT, published in July 2024. Since then, we’ve extended the vision to the physical layer — see RF-GPT: Teaching Language Models to See the Invisible Spectrum, where we give a language model its first glimpse of radio-frequency signals. If you’re working on domain-adapted LLMs for telecom or related fields, feel free to connect with me on LinkedIn.